# Intro to Pipeline Automation


#### Introduction
Humans are always looking for simpler and more efficient ways to do things. Just as we started programming and developing software, we were looking for ways to automate some of the tasks. Today, automation is heavily ingrained in the Software Development Life Cycle (SDLC) and DevOps processes. While this is incredibly good for production, allowing for faster development and deployment, it does, however, introduce new security risks. When these processes are manual, an attacker would have to compromise the credentials or workstation of the individual that performed the relevant process. However, with automation, an attacker can now go after the pipeline itself.
Learning Objectives
This room will teach you about the following concepts:
* Introduction to the DevOps pipeline
* Introduction to DevOps tools and automation
* Introduction to security principles for the DevOps pipeline
This is the introduction room. As such, most of these concepts will only be introduced in this room and will be covered in more detail in the rest of the rooms in this module.
Answer the questions below
I'm ready to learn about pipeline automation and how to make sure it is secure!
Completed
#### DevOps Pipelines Explained
Before learning about automation security, we should start by defining the pipeline and showing where automation can take place. The diagram below shows what a typical pipeline can look like, as well as the software that could be used for this purpose:
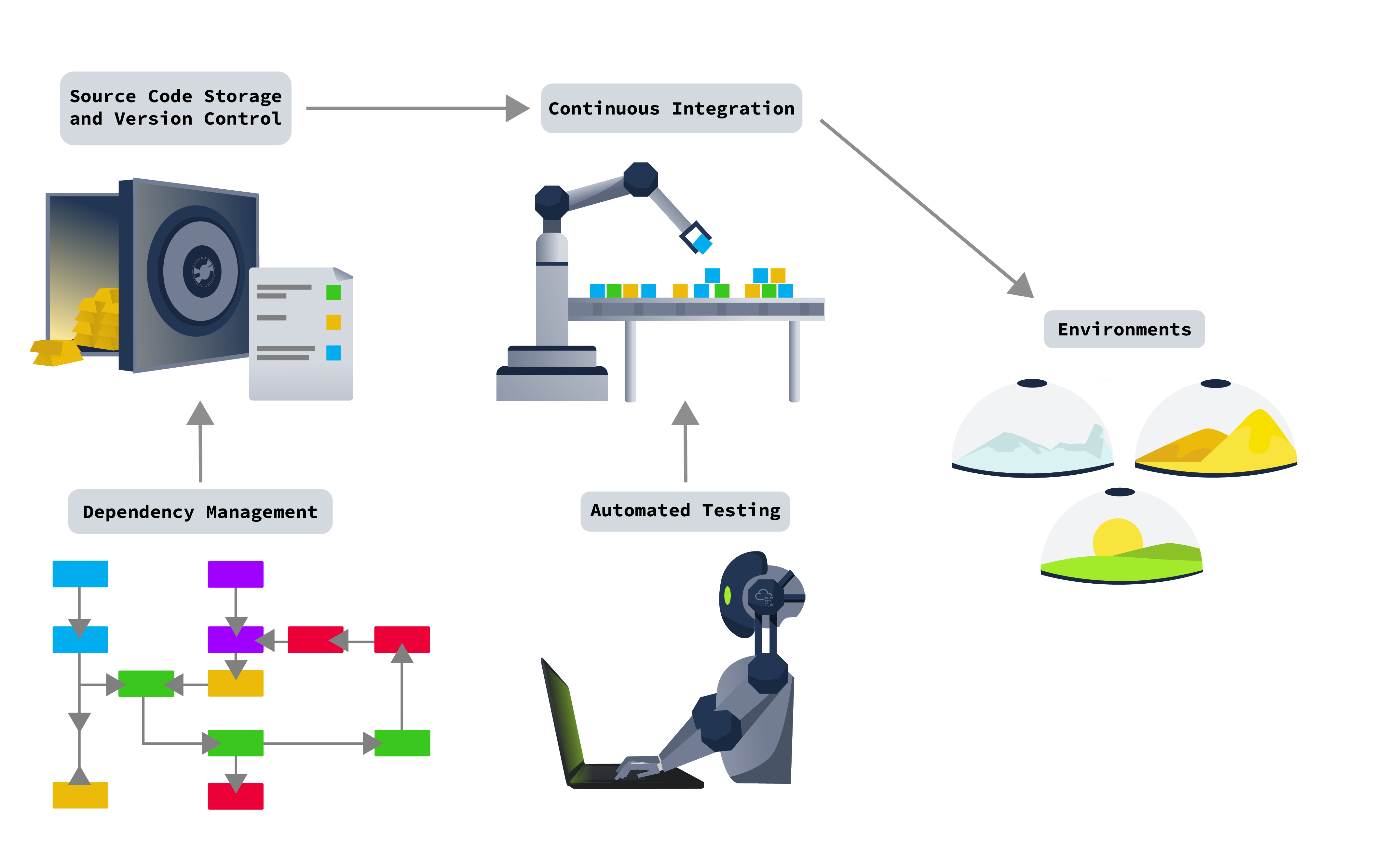
For each of these items, we will look at what they are, the common tools used for them, an introduction to their security, and a case study of what can happen when security fails. Each of these components will be reviewed in-depth in the coming rooms of this module.
Answer the questions below
Where in the pipeline is our end product deployed?
Look at the last block in the diagram
*Environment*
#### Source Code and Version Control

Let's take a look at source code and version control. This is the start of our pipeline. We need a location where we can store our code. Furthermore, we often want to keep several versions of our code since we are continuously making improvements and adding features.
Source Code Storage
We need to consider several things when deciding where to store our code:
* How can we perform access control for our source code?
* How can we make sure that changes made are tracked?
* Can we integrate our source code storage system with our development tools?
* Can we store and actively use multiple different versions of our source code?
* Should we host our source code internally, or can we use an external third party to host our code?
The answers to these questions will help us choose the correct source code storage solution for our project.
Version Control
We need version control for two main reasons:
* We are often integrating new features in our software. Modern development approaches, such as Agile, means we are constantly updating our code. To keep all of these updates in check, we need version control.
* An entire development team is working on the code, not just one developer. To ensure that we can integrate the changes from multiple developers, version control is required.
Version control allows us to keep multiple versions of the code. This can be the specific version each developer is working on, but it can also be completely different versions of our application, including minor and major versions.
Common Tools
The two most common source code storage and version control systems are Git and SubVersion (SVN). Git is a distributed source control tool, meaning that each contributor will have their own copy of the source code. On the other hand, SVN is a centralised source control tool, meaning the control of the repo is managed centrally.
GitHub is by far the largest provider of Internet hosting for software development and version control using Git. You can create a GitHub account and use that to manage your source code repositories (repo). However, you could also host your own git server using software such as Gitlab. For SVN, the two most popular tools are TortoiseSVN and Apache SVN.
However, it should be noted that source code storage solutions such as Gitlab provide much more features than simple storage and version control. Today, these tools can be used for almost the entire pipeline!
Security Considerations
Our source code is often our secret sauce. As such, we want to make sure it is not exposed. This is why authentication and access control for our source code is so important. We also want to make sure that changes and updates are adequately tracked, allowing us to always go back to a previous version if something happens.
However, we also need to be careful about what we store as part of our source code. Source code cannot be fully secret since developers need access to it. As such, we should be careful not to confuse source code storage with secret management. We need to make sure not to store secrets, such as database connection strings and credentials, in our source code. Since we keep all versions of our source code, even if we remove the secrets in a newer version, they will still be exposed in the previous versions.
Case Study: Git Never Forgets
As mentioned before, version control can end badly for us if we make a mistake. This is a common problem when using version control tools such as Git. There is a saying: *"Git never forgets"*. Code is "committed" to a Git repo. When this happens, Git determines the changes made to the files and creates a new version based on these changes. Any user with access to the repo can look at historical commits and the changes that were made.
What can often happen is a developer accidentally commits secrets such as credentials or database connection strings to a Git repo. Realising their mistake, they delete the secrets and create another commit. However, the repo will now have both commits. If an attacker got access to the repo, they could use a tool such as [GittyLeaks](https://github.com/kootenpv/gittyleaks), which would scan through the commits for sensitive information. Even if this information no longer exists in the current version, these tools can scan through all previous versions and uncover these secrets.
Answer the questions below
```
┌──(kali㉿kali)-[~/Downloads]
└─$ export PATH=/home/kali/.local/bin:$PATH
┌──(kali㉿kali)-[~/Downloads]
└─$ gittyleaks -link https://github.com/kootenpv/yagmail
--------------------------------------------------------------------------------
gittyleaks' Bot Detective at work ...
--------------------------------------------------------------------------------
----------------------------------------
yagmail/oauth2.py: for param in sorted(params.items(), key=lambda x: x[0]):
yagmail/oauth2.py: "google_refresh_token": google_refresh_token}
yagmail/sender.py: self.smtp_skip_login = smtp_skip_login
docs/conf.py: 'github_user': "kootenpv",
yagmail/oauth2.py: auth_string = 'user=%s\1auth=Bearer %s\1\1' % (username, access_token)
tests/test_dkim.py: yag.login = Mock()
README.md: private_key=private_key,
yagmail/dkim.py: private_key: bytes
yagmail/yagmail.py: self.smtp_skip_login = smtp_skip_login
yagmail/sender.py: user = find_user_home_path()
tests/test_dkim.py: private_key=private_key,
README.md: private_key = Path("privkey.pem").read_bytes()
```
Who is the largest online provider of Git?
*Github*
What popular Git product is used to host your own Git server?
*Gitlab*
What tool can be used to scan the commits of a repo for sensitive information?
*GittyLeaks*
#### Dependency Management

Let's talk about dependencies. Although we might think that we are writing a large amount of code when we develop, the truth is that it is only the tip of the iceberg. Unless you are coding in binary, chances are you are actually only writing a fraction of the actual code. This is because a lot of the code has already been written for us in the form of libraries and software development kits (SDKs). Even variables like String in an application have an entire library behind them! The management of these dependencies is a vital part of the pipeline.
External vs Internal Dependencies
External dependencies are publicly available libraries and SDKs. These are hosted on external dependency managers such as PyPi for Python, NuGet for .NET, and Gems for Ruby libraries. Internal dependencies are libraries and SDKs that an organisation develops and maintains internally. For example, an organisation might develop an authentication library. This library could then be used for all applications developed by the organisation.
There are different security concerns for internal and external dependencies:
Internal
External
Libraries can often become legacy software since they no longer receive updates or the original developer has left the company.
Since we do not have full control over the dependency, we must perform due diligence to ensure that the library is secure.
The security of the package manager is our responsibility for internal libraries.
If a package manager or content distribution network (CDN) is compromised, it could lead to a supply chain attack.
A vulnerability in an internal library could affect several of our applications since it is used in all of them.
External libraries can be researched by attackers to discover 0day vulnerabilities. If such a vulnerability is found, it could lead to the compromise of several organisations at the same time.
Common Tools
A dependency manager, also called a package manager, is required to manage libraries and SDKs. As mentioned before, tools such as PyPi, NuGet, and Gems are used for external dependencies. The management of internal dependencies is a bit more tricky. For these, we can use tools such as JFrog Artifactory or Azure Artifacts to manage these dependencies.
Security Considerations
Some of the security considerations have been mentioned before. However, the primary security concern is that dependencies are code outside our control. Especially in modern times, where so many different dependencies are used, it is incredibly hard to track dependencies. If there are any vulnerabilities in these dependencies, it could lead to vulnerabilities in our application.
Case Study: Log4Shell
A 0day vulnerability was discovered in Log4j dependency in 2021 called Log4Shell. Log4j is a Java-based logging utility. It is part of the Apache Logging Services, a project of the Apache Software Foundation. The vulnerability could allow an unauthenticated attacker to gain remote code execution on a system that makes use of the logger. The true issue? This small little dependency was used almost literally everywhere, as shown by this [XKCD](https://xkcd.com/2347/) cartoon:

This is not an over-exaggeration. Have a look [here](https://github.com/cisagov/log4j-affected-db/tree/develop/software_lists) to see how many different products were vulnerable since they used this dependency. The list got so big that they had to split it alphabetically. This shows the impact of what can happen when a vulnerability is discovered in a dependency.
Answer the questions below
What do we call the type of dependency that was created by our organisation? (Internal/External)
*Internal*
What type of dependency is JQuery? (Internal/External)
*External*
What is the name of Python's public dependency repo?
*Pypi*
What dependency 0day vulnerability set the world ablaze in 2021?
*Log4j*
#### Automated Testing

Let's take a closer look at automated testing. In the old days, testing was quite a tedious and manual process. A tester would have to manually run and document every test case and hope that the coverage was sufficient to ensure that the application or service works and will remain stable. However, in modern pipelines, automated testing can do a significant portion of this.
Unit Testing
When talking about automated testing in a pipeline, this will be the first type of testing that most developers and software engineers are familiar with. A unit test is a test case for a small part of the application or service. The idea is to test the application in smaller parts to ensure that all the functionality works as it should.
In modern pipelines, unit testing can be used as quality gates. Test cases can be integrated into the Continuous Integration and Continuous Deployment (CI/CD) part of the pipeline, where the build will be stopped from progressing if these test cases fail. However, unit testing is usually focused on functionality and not security.
Integration Testing
Another common testing method is integration testing. Where unit tests focus on small parts of the application, integration testing focuses on how these small parts work together. Similar to unit tests, testing will be performed for each of the integrations and can also be integrated into the CI/CD part of the pipeline. A subset of integration testing is regression testing, which aims to ensure that new features do not adversely impact existing features and functionality. However, similar to unit testing, integration testing, including regression testing, is not usually performed for security purposes.
Security Testing
So if the first two types of automated testing are not for security testing, which are? There are two primary types of automated security testing.
SAST
Static Application Security Testing (SAST) works by reviewing the source code of the application or service to identify sources of vulnerabilities. SAST tools can be used to scan the source code for vulnerabilities. This can be integrated into the development process to already highlight potential issues to developers as they are writing code. We can also integrate this into the CI/CD process. Not as quality gates, but as security gates, preventing the pipeline from continuing if the SAST tool still detects vulnerabilities that have not been flagged as false positives.
DAST
Dynamic Application Security Testing (DAST) is similar to SAST but performs dynamic testing by executing the code. This allows DAST tools to detect additional vulnerabilities that would not be possible with just a source code review. One method that DAST tools use to find additional vulnerabilities, such as Cross Site Scripting (XSS), is by creating sources and sinks. When a DAST tool provides input to a field in the application, it marks it as a source. When data is returned by the application, it looks for this specific parameter again and, if it finds it, will mark it as a sink. It can then send potentially malicious data to the source and, depending on what is displayed at the sink, determine if there is a vulnerability such as XSS. Similar to SAST, DAST tools can be integrated into the CI/CD pipeline as security gates.
Penetration Testing
Sadly, SAST and DAST tools cannot fully replace manual testing, such as penetration tests. There have been significant advancements in automated testing and even in some cases, these techniques were combined with more modern approaches to create new testing techniques such as Interactive Application Security Testing (IAST) and Runtime Application Self-Protection (RASP). However, the main issue remains that these tools, including these modern testing techniques, do not perform well against contextual vulnerabilities. Take the process flow of a payment, for example. A common vulnerability is when part of the process can be bypassed, for example, the credit card validation step. This is an easy test case to perform manually, but since it requires context, even DAST tooling will find it hard to discover the bypass. Similarly, business logic and access control flaws are hard to discover using automated tools, whereas manual testing can discover them fairly quickly. It is not that automated tooling will never be able to find these flaws, it is simply more cost-effective to use manual testing.
Common Tools
There are several common tools that can be used for automated testing. Both [GitHub](https://github.com/features/security/code) and [Gitlab](https://docs.gitlab.com/ee/user/application_security/sast/) have built-in SAST tooling. Tools such as [Snyk](https://snyk.io/) and [Sonarqube](https://www.sonarqube.org/) are also popular for SAST and DAST.
Case Study: She cannae take any more captain, She's gonna blow!\
A common issue with SAST and DAST tooling is that the tool is simply deployed into the pipeline, even simply for a Proof-of-Concept (PoC). However, you need to take several things into consideration:
* Performance cost
* Integration points
* Calibration of results
* Quality and security gate implementation
The first and last point is very important and can be costly if ignored. The initial PoC of the tool should probably occur after hours since it will have to scan through all code. This process can impact the performance of your source code control tool significantly. Imagine this happening just before a big release, and developers cannot stage and push their latest commits.
Furthermore, as more organisations move to a more agile approach to software development, most repos receive several hundred commits daily. If you introduce a new security gate, even just for a PoC, that scans each merge request for vulnerabilities before approval, this can have a drastic performance cost on your infrastructure and the speed at which developers can perform merge requests.
When introducing new automated testing tooling, careful consideration should be given to how a PoC should be performed to ensure that no disruptions are caused but also to ensure that the PoC is representative of how the tooling will interact when it is finally integrated. A fine balance to try and achieve!
Answer the questions below
```
Automated testing is a process of using software to perform tests on a software application automatically, without manual intervention. It helps to catch bugs and ensure that the application behaves as expected. Automated testing can include unit tests, integration tests, and end-to-end tests, and can be run on a schedule or triggered by code changes. The main benefits of automated testing include faster testing, improved accuracy, and the ability to test the application more thoroughly.
There are many tools available for automated testing. Some popular tools for different types of testing include:
- Unit Testing: JUnit (Java), NUnit (.NET), pytest (Python)
- Integration Testing: Jenkins, Travis CI
- End-to-end Testing: Selenium, Appium
- Functional Testing: TestCafe, Cypress
- Performance Testing: Apache JMeter, Gatling
These are just a few examples, and the choice of tool depends on the specific requirements of the project and the technology stack being used.
```
What type of tool scans code to look for potential vulnerabilities?
*SAST*
What type of tool runs code and injects test cases to look for potential vulnerabilities?
*DAST*
Can SAST and DAST be used as a replacement for penetration tests? (Yea,Nay)
*Nay*
#### Continuous Integration and Delivery

In modern pipelines, software isn't manually moved between different environments. Instead, an automated process can be followed to compile, build, integrate, and deploy new software features. This process is called CI/CD.
*Note: The term CI/CD has changed quite a bit in recent years. Initially, the primary focus was just on making sure that development was performed using an Agile approach while delivery of the product still occurred using the waterfall model of only deploying final releases. During this time, it was common for CI/CD to mean Continuous Integration and Continuous Development. However, quickly it was realised that deployment itself could also be made Agile and the acronym changed to mean Continuous Integration and Continuous Deployment, with development now becoming part of the Integration component. Finally, they realised that it is not just the deployment, but all aspects around the delivery of the solution and how we monitor it after delivery and the acronym was again changed to now finally mean Continuous Integration and Continuous Delivery. So you might hear these terms used interchangeably, but they all actually refer to the same thing.*
CI/CD
Since we are constantly building new features for our system or service, we need to ensure that these features will work with the current application. Instead of waiting until the end of the development cycle when all features will be integrated, we can now continuously integrate new features and test them as they are being developed.
We can create what is called a CI/CD pipeline. These pipelines usually have the following distinct elements:
* Starting Trigger - The action that kicks off the pipeline process. For example, a push request is made to a specific branch.
* Building Actions - Actions taken to build both the project and the new feature.
* Testing Actions - Actions that will test the project to ensure that the new feature does not interfere with any of the current features of the application.
* Deployment Actions - Should a pipeline succeed, the deployment actions detail what should happen with the build. For example, it should then be pushed to the Testing Environment.
* Delivery Actions - As CI/CD processes have evolved, the focus is now no longer just on the deployment itself, but all aspects of the delivery of the solution. This includes actions such as monitoring the deployed solution.
CI/CD pipelines require build-infrastructure to execute the actions of these elements. We usually refer to this infrastructure as build orchestrators and agents. A build orchestrator directs the various agents to perform the actions of the CI/CD pipelines as required.
These CI/CD pipelines are usually where the largest portion of automation can be found. As such, this is usually the largest attack surface and the biggest chance for misconfigurations to creep in.
Common Tools
GitHub and Gitlab provide CI/CD pipeline capabilities and are quite popular to use. GitHub provides build agents, whereas Gitlab provides a Gitlab runner application that can be installed on a host to make it a build agent. For more complex builds, build orchestrator software such as Jenkins can be used. We will explore these tools and their common misconfigurations in later rooms.
Case Study: A tangle between Dev and Prod
One common misconfiguration with CI/CD pipelines is using the same build agents for both Development (DEV) and Production (PROD) builds. This creates an interesting problem since most developers will have access to the starting trigger for a DEV build but not a PROD build.
If one of these developers were compromised, an attacker could leverage their access to cause a malicious DEV build that would compromise the build agent. This would not be a big issue if the build agent was just used for DEV builds. However, since this agent is also used for PROD builds, an attacker could just persist on this build agent until a PROD build is actioned to inject their malicious code into the build, which would allow them to compromise the production build of the application.
Answer the questions below
What does CI in CI/CD stand for?
*Continuous Integration*
What does CD in CI/CD stand for?
*Continuous Delivery*
What do we call the build infrastructure element that controls all builds?
*build orchestrator*
What do we call the build infrastructure element that performs the build?
*build agent*
#### Environments

Let's zoom in a bit on the pipeline section of Environments. Most pipelines have several environments. Each of these environments has a specific use case, and their security posture often differs. Let's take a look at some of the common ones:
**Environment**
**Description**
**Stability**
**Security Posture**
**May it contain customer data?**
DEV - Development
The DEV environment is the playground for developers. This environment is the most unstable as developers are continuously pushing new code and testing it. From a security standpoint, this environment has the weakest security. Access control is usually laxer, and developers often have direct access to the infrastructure itself. The likelihood of the development environment being compromised is high, but if there is adequate segregation, the impact of such a compromise should be low.
Unstable
Weakest
No
UAT - User Acceptance Testing
The UAT environment is used to test the application or select features before they are pushed to production. These include unit tests that ensure the developed feature behaves as expected. This can (and should) include security tests as well. Although this environment is more stable than DEV, it can often still be fairly unstable. Similarly, certain security hardening controls would have been introduced for UAT, but it is still not as hardened as PreProd or PROD.
Semi-Stable
Second Weakest
No
PreProd - Pre-Production
The PreProd environment is used to mimic production without actual customer/user data. This environment is kept stable and used to perform the final tests before the new feature is pushed to production. From a security standpoint, PreProd's security should technically mirror PROD. Although, this is not always the case.
Stable
Second Strongest
No
PROD - Production
The PROD environment is the most sensitive. This is the current active environment that serves users or customers. To ensure that our users have the best experience, this environment must be kept stable. No updates should be performed here without proper change management. To enforce this, the security of this environment is the strongest. Only a select few employees or services will have the ability to make changes here. Furthermore, since we may have "malicious" users, the security has to be hardened to prevent outsider threats as well.
Stable
Strongest
Yes
DR/HA - Disaster Recovery or High Availability
Depending on the criticality of the system, there may be a DR or HA environment. If the switchover is instantaneous, it is usually called a HA environment. This is often used for critical applications such as Online Banking, where the bank has to pay large penalties if the website goes down. In the event where some (but still small) downtime is allowed, the environment is called a DR environment, meant to be used to recover from a disaster in production. DR and HA environments should be exact mirrors of PROD in both stability and security.
Stable
Strongest
Yes
Other Notable Environments
There are some other environments that you may hear about when talking about DevOps.
**Green and Blue Environments**
Green and Blue environments are used for a Blue/Green deployment strategy when pushing an update to PROD. Instead of having a single PROD instance, there are two. The Blue environment is running the current application version, and the Green environment is running the newer version. Using a proxy or a router, all traffic can then be switched to the Green environment when the team is ready. However, the Blue environment is kept for some time, meaning that if there are any unforeseen issues with the new version, traffic can just be routed to the Blue environment again. We can think of this as High-Availability backups of PROD during a new deployment to use for a roll-back if something goes wrong, which is faster than having to perform a roll-back of the actual PROD environment.
**Canary Environments**
Similar to Green and Blue environments, the goal of Canary environments is to smooth the PROD deployment process. Again two environments are created, and users are gradually moved to the new environment. For example, at the start, 10% of users can be migrated. If the new environment remains stable, another 10% can be migrated until 100% of the users are in the new environment. Again, these are usually classified under PROD environments but are used to reduce the risk associated with a PROD upgrade to limit potential issues and downtime.
Common Tools
Environments have changed significantly in modern times. Breakthroughs such as virtualisation and containerisation have changed the landscape. Instead of environments simply being computers, we can now have virtual computers created through tools such as Vagrant or Terraform. We could also move away from hosts entirely to things like containers using Docker or pods using Kubernetes. These tools can make use of processes such as Infrastructure as Code (IaC) to even create software that can create and manage these environments.
Security Considerations
As mentioned before, the security considerations become more important the closer the environment is to PROD. The underlying infrastructure of an application also forms part of the attack surface of the actual application. Any vulnerabilities in this infrastructure could allow an attacker to take control of the host and the application. As such, the infrastructure must be hardened against attacks. This hardening process usually requires things like the following:
* Removing unnecessary services
* Updating the host and applications
* Using a firewall to block unused ports
Case Study - Developer Bypasses in PROD
One of the common issues that can happen with different environments is that often things that should stay in DEV, don't. Develop bypasses are common in DEV environments for features like the following:
* Multi-factor authentication
* CAPTCHAs
* Password resets
* Login portals
Developer bypasses allow developers to quickly test different application features by bypassing time-consuming features such as MFA prompts. A common example is having a specific One-Time Pin (OTP) code that is always accepted, regardless of the OTP code that is sent by the application.
However, if there is inadequate sanitisation of these bypasses before the application is moved to the next environment, it could lead to a developer bypass making its way all the way into PROD. That OTP bypass? It could now be leveraged by an attacker to bypass MFA and compromise user accounts.
This is why environments must be segregated, and similar to quality gates, security gates must be implemented to ensure a clean application is moved to the next environment.
Answer the questions below
Which environment usually has the weakest security configuration?
*DEV*
Which environment is used to test the application?
*UAT*
Which environment is similar to PROD but is used to verify that everything is working before it is pushed to PROD?
*PreProd*
What is a common class of vulnerabilities that is discovered in PROD due to insecure code creeping in from DEV?
Think about who is introducing this vulnerability
*Developer Bypasses*
#### Challenge
View SiteOpen the site and build your own pipeline to get your flag. Use what you learned to determine which concerns are valid at which stages of the pipeline!
Answer the questions below
What is the flag received after successfully building your pipeline?
*THM{Pipeline.Automation.Is.Fun}*
#### Conclusion
Automation in the pipeline has significantly increased the capability of SDLC processes. It has enabled developers to rapidly create and deploy updates to applications. However, these new automation can also lead to an increased attack surface since an attacker can now indirectly attack the application by compromising its pipeline. Implementing secure automation is therefore needed to ensure that the automated pipeline does not increase the risk of application compromise.
Throughout the various rooms in this module, we will take a deeper dive into the elements that make up a pipeline and show how security can be applied to each to create a secure, automated pipeline.
Answer the questions below
I understand the basic pipeline structure, and I'm ready to do a deep dive into each element!
Completed
\[\[Intro to Containerisation]]
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://jesusgavancho.gitbook.io/writeups/intro-to-pipeline-automation.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.